分布式存储
一、概述
把多台存储服务器的存储组合成一个整体,再通过网络进行远程共享
远程存储优点: 统一管理,按需所取(
在线扩容),HA、LB存储类型分类:文件存储(NAS)、块存储(SAN)、对象存储
存储分类
| 分类 | 描述 | |
|---|---|---|
| 直连式存储 | DAS(Direct Attach Storage) | 通过接口直接连接到机器总线上 eg: U盘、移动硬盘 |
| 网络附加存储 | NAS(Network Attach Storage) | 通过交换机,路由器连接,共享的是目录 eg: nfs、samba、ftp可以实现数据同步 |
| 存储区域网络 | SAN(Storage Area Network) | 通过交换机,路由器连接,共享的块设备 实现 不了数据同步 |
二、SAN
存储区域网络 ,Storage Area Network
目前常见的SAN有
FC-SAN和IP-SAN,其中FC-SAN为通过光纤通道协议转发SCSI协议,IP-SAN通过TCP协议转发SCSI协议更多:百科 )
1.安装
配置epel源
rpm -ivh https://mirrors.aliyun.com/epel/epel-release-latest-7.noarch.rpm
yum makecache①服务端安装
yum install scsi-target-utils -y②客户端安装
yum install iscsi-initiator-utils -y2.配置
①服务端配置
vim /etc/tgt/targets.conf
#添加如下内容,来自子配置文件 /etc/tgt/conf.d/sample.conf
<target iscsi:data1>
backing-store /dev/sdb
</target>启动服务
systemctl enable tgtd
systemctl start tgtd
lsof -i:3260②客户端
#1.发现服务端共享的设备
iscsiadm -m discovery -t sendtargets -p 10.1.1.91
#2.登录使用
iscsiadm -m node -l
#3.验证
fdisk -l
df -h
#3.取消登录
iscsiadm -m node -u
#4.删除发现信息
iscsiadm -m node --op delete三、Glusterfs
它是一个免费且开源的
分布式文件系统提供多种模式可选:
replica、stripe、distributed、distributed-replica、dispersed等(各个模式类似RAID级别)分布式存储优点:①扩容方便②提升读写性能③避免单个节点故障
机器准备
| Host name | IP | Hostname |
|---|---|---|
| Storage1 | 10.1.1.91 | s1.tigeru.cn |
| Storage2 | 10.1.1.92 | s2.tigeru.cn |
| Storage3 | 10.1.1.93 | s3.tigeru.cn |
| Storage4 | 10.1.1.94 | s4.tigeru.cn |
| Client1 | 10.1.1.95 | c1.tigeru.cn |
| Client2 | 10.1.1.96 | c2.tigeru.cn |
1.安装
第一步:配置yum源
# vim /etc/yum.repos.d/glusterfs.repo
[glusterfs]
name=glusterfs
baseurl=https://buildlogs.centos.org/centos/7/storage/x86_64/gluster-4.1/
enabled=1
gpgcheck=0第二步:安装并启动
yum install glusterfs-server
systemctl start glusterd
systemctl enable glusterd
#查看日志
/var/log/glusterfs/glusterd.log第三步:存储服务器建立连接
注意:只需要在一台机器上执行即可,这里我们是在10.1.1.91;IP也可以换做主机名
gluster peer probe 10.1.1.92
gluster peer probe 10.1.1.93
gluster peer probe 10.1.1.94
#每台机器上查看状态
gluster peer status第四步:客户端安装
#安装(需要配置yum源)
yum install glusterfs glusterfs-fuse -y2.基本使用
(1)节点操作
#查看节点信息
gluster peer status
#添加节点(IP可以换为主机名)
gluster peer probe 10.1.1.92
#删除节点
gluster peer detach 10.1.1.92 (2)卷操作
#列出所有卷名称
gluster volume list
#创建卷
gluster volume create 卷名 模式 机器数量 节点信息 格式[IP/主机名]:目录
#案例
gluster volume create gv0 replica 2 10.1.1.91:/data/gv0/ 10.1.1.92:/data/gv0/
#查看卷信息
gluster volume info [卷名]
#删除卷
gluster volume delete 卷名
#开启卷
gluster volume start 卷名
#关闭卷
gluster volume stop 卷名(3)删除卷
①客户端卸载目录②服务端停止卷③删除卷
#客户端
umount /挂载点
#停止卷
gluster volume stop 卷名
#删除卷
gluster volume delete 卷名(4)扩容
注意:仅支持Distribute模式扩容
#第一步:新添加的存储服务器安装服务器软件包,启动服务
#第二步:加入机器到集群
gluster peer probe storage5
#第三步:扩容
gluster volume add-brick gv1 storage4:/data/gv1 force
#裁剪
#gluster volume remove-brick gv1 storage4:/data/gv1 force 2. replica
复制,镜像存储,类型
RAID1
服务器开启
注意:只需要在一台机器上创建,为了方便操作,目录是建在根分区下创建的,所以需要加force,生产环境下不要这样操作;每台机器上创建目录,可以不一致
#创建目录(每台存储服务器)
mkdir /data/gv0
#创建
gluster volume create gv0 replica 4 10.1.1.91:/data/gv0/ 10.1.1.92:/data/gv0/ 10.1.1.93:/data/gv0/ 10.1.1.94:/data/gv0/ force
#查看状态
#(Status:Created Type: Replicate)
gluster volume info gv0
#启动
#启动后状态为(Status:Started)
gluster volume start gv0客户端测试
#挂载(任意一台存储服务器即可,IP也可换为主机名)
mount -t glusterfs 10.1.1.91:gv0 /test
#验证
df -h可以在另一台客户端挂载,测试数据的同步
3. stripe
条带化,磁盘利用率
100%,提高IO性能,类似RAID0大文件会平均分配给存储节点(LB)
没有
HA,当一天机器挂载,则服务不可用
服务端开启
#创建目录(每台存储服务器)
mkdir /data/gv0
#创建卷
gluster volume create gv0 stripe 4 10.1.1.91:/data/gv0/ 10.1.1.92:/data/gv0/ 10.1.1.93:/data/gv0/ 10.1.1.94:/data/gv0/ force
#开启卷
gluster volume start gv0客户端测试
#挂载使用
mount.glusterfs s1.tigeru.cn:gv0 /test2/
#创建测试文件(tmp2.test)大小为100M
dd if=/dev/zero of=/test2/tmp2.test bs=1M count=100
#然后去每个存储服务端查看,可以发现每一个服务端上文件(tmp2.txt)的大小为25M4. distribute
默认模式,分布式,随机写,磁盘利用率
100%,方便扩容但是不能保证数据安全性,挂掉一台机器那台机器上的数据就会丢失
服务端开启
#创建目录(每台存储服务器)
mkdir /data/gv1
#创建卷, distribute 可省略(默认值)
gluster volume create gv1 10.1.1.91:/data/gv1/ 10.1.1.92:/data/gv1/ 10.1.1.93:/data/gv1/ 10.1.1.94:/data/gv1/ force
#开启卷
gluster volume start gv1客户端测试
#挂载使用
mount.glusterfs s1.tigeru.cn:gv1 /test4/
#测试
touch /test4/{1..100}.txt
#服务端查看所创建的文件(每台存储服务器),会发现创建的文件会平均分配到每台机器上5. distributed-replica
分布式-高可用,可解决单点故障,可扩容(得添加一个组),利用率
50%假设现在有4个存储,则会分为两个组,这两个组按照
distributed模式随机写文件,但在组内的两个存储会按replica模式镜像复制
服务端
#创建目录(每台存储服务器)
mkdir /data/gv3
#创建时指定2台镜像,实际有4台,表示组建两个组
#当指定2台镜像,实际有6台,则表示创建三个组
gluster volume create gv3 replica 2 s1.tigeru.cn:/data/gv3/ s2.tigeru.cn:/data/gv3/ s3.tigeru.cn:/data/gv3/ s4.tigeru.cn:/data/gv3/ force
#查看状态,可以看到状态为(Type: Distributed-Replicate)
gluster volume info gv3
#开启卷
gluster volume start gv3客户端
#挂载使用
mount.glusterfs s1.tigeru.cn:gv3 /test3/
#测试
touch /test3/1.txt
#服务端查看(每台存储服务器),会发现两台服务器目录有同样内容(这两台机器为一组,做数据镜像)
ls /data/gv36. dispersed
类似
RAID5
#创建目录(每台存储服务器)
mkdir /data/gv4
#创建 (redundancy ),会提示创建一个冗余
gluster volume create gv4 disperse 4 s{1..4}.tigeru.cn:/data/gv4/ force
#gluster volume create gv4 disperse 4 redundancy 1 s{1..4}.tigeru.cn:/data/gv4/ force
#创建,实现两个冗余
gluster volume create gv4 disperse 5 redundancy 2 s{1..5}:/data/gv4/ force
#查看状态
gluster volume info gv4
#开启卷
gluster volume start gv4客户端使用
#挂载使用
mount.glusterfs s1.tigeru.cn:gv4 /test4/
#测试
dd if=/dev/zero of=/test4/1.test bs=1M count=100
#然后去每个存储服务端查看,可以发现每一个服务端上文件(1.test)的大小为34M
ls /data/gv47.更多
官网教程:
四、Ceph
分布式文件存储系统
Ceph 存储集群至少需要一个 Ceph Monitor 和两个 OSD 守护进程
Ceph 支持三种存储接口:对象存储 RGW(rados gateway)、块存储 RBD(rados block device) 和文件存储 CephFS
Ceph 由储存管理器(Object storage cluster对象存储集群,即:Osd守护进程)、,集群监视器(Ceph Monitor)和元数据服务器(Metadata server cluster, mds)构成。
官方文档: http://docs.ceph.org.cn/
更多可参考:
https://juejin.im/entry/5b3ae5de518825624e14256c
1.机器准备
| Hostname | IP |
|---|---|
| client | 10.1.1.90 |
| node1 | 10.1.1.91 |
| node2 | 10.1.1.92 |
| node3 | 10.1.1.93 |
2.安装前准备
(1)每台虚拟机添加一块10G硬盘
(2)配置yum源
# Epel 源
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
# Cenos 源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repoceph源
# vim /etc/yum.repos.d/ceph.repo
[ceph]
name=ceph
baseurl=http://mirrors.aliyun.com/ceph/rpm-mimic/el7/x86_64/
enabled=1
gpgcheck=0
priority=1
[ceph-noarch]
name=cephnoarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/
enabled=1
gpgcheck=0
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-mimic/el7/SRPMS
enabled=1
gpgcheck=0
priority=1(3)注意事项
①时间同步
②主机名配置,不要配置为node.tigeru.cn这种格式
3.安装
第一步:ceph集群安装ceph
#每台ceph服务器都安装
yum install ceph ceph-radosgw -y
#查看版本
ceph -v注意:如果网络比较好,可以采用ceph-deploy install node1 node2 node3来安装
第二步:客户端安装 ceph-common
yum install ceph-common -y第三步:创建集群
选择一台机器进行集群创建,我这里选择node1
为了方便后续配置,在node1上进行免密配置
ssh-keygen
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
ssh-copy-id client安装部署工具
yum install ceph-deploy -y创建集群
#创建集群配置文件目录
mkdir /etc/ceph
cd /etc/ceph
#创建集群
ceph-deploy new node1
第四步:安装监控mon
node1开启监控
vim /etc/ceph/ceph.conf
#最后添加如下内容,写上要监控的网关
public network = 10.1.1.0/24监控节点初始化
ceph-deploy mon create-initial
#查看health
ceph health
将配置文件信息同步到所有节点
ceph-deploy admin node1 node2 node3
为了防止mon单点故障,你可以加多个mon节点(建议奇数个,因为有quorum仲裁投票)
ceph-deploy mon add node2
ceph-deploy mon add node3
查看状态
ceph -s
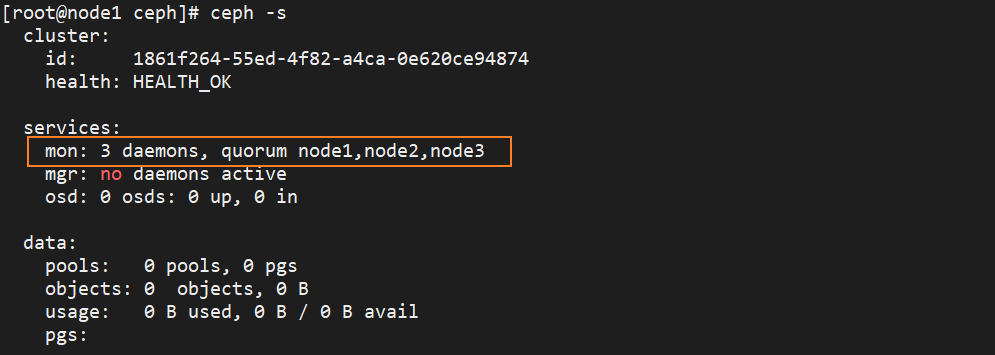
问题:
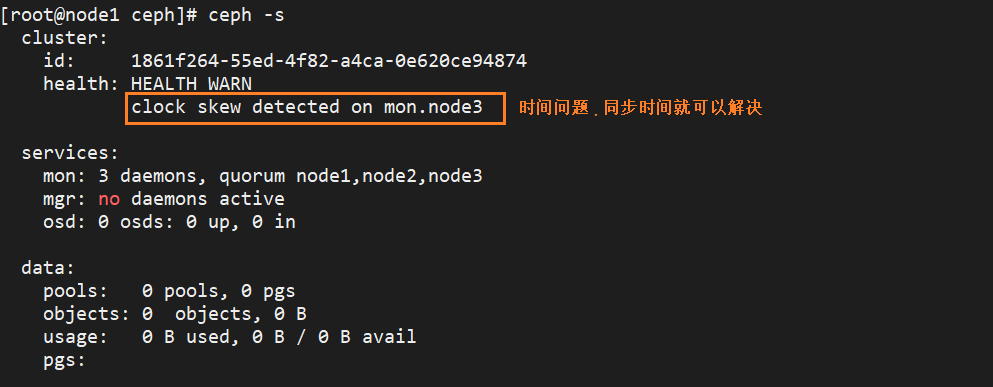
解决方法一:
创建计划任务,定时同步时间
解决方法二:
调大时间警告的阈值:
vim /etc/ceph/ceph.conf
#添加如下内容
# monitor间的时钟滴答数(默认0.5秒)
mon clock drift allowed = 2
# 调大时钟允许的偏移量(默认为5)
mon clock drift warn backoff = 30
#同步到所有节点
ceph-deploy --overwrite-conf admin node1 node2 node3
#所有节点重启服务
systemctl restart ceph-mon.target
第五步: 创建mgr(管理)
cd /etc/ceph/
ceph-deploy mgr create node1
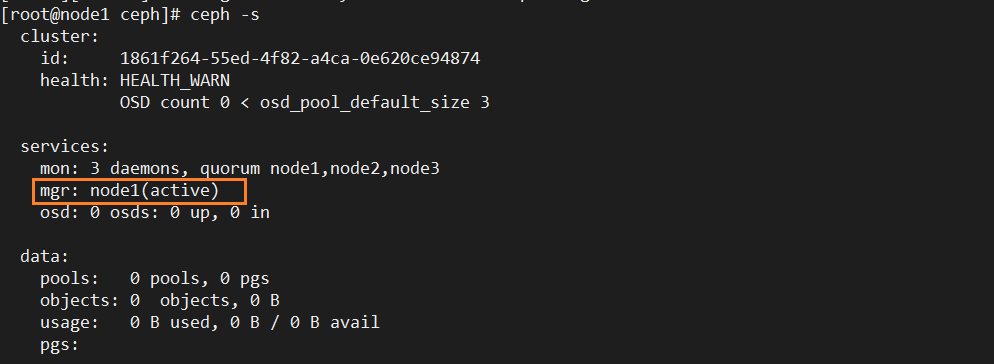
添加多个mgr实现HA
ceph-deploy mgr create node2
ceph-deploy mgr create node3
第六步:创建osd存储盘
所有操作的是在node1上执行
#1.查看节点上磁盘信息
ceph-deploy disk list node1
ceph-deploy disk list node2
ceph-deploy disk list node3
#2.格式化磁盘数据
ceph-deploy disk zap node1 /dev/sdb
ceph-deploy disk zap node2 /dev/sdb
ceph-deploy disk zap node3 /dev/sdb
#3.将磁盘创建为osd
ceph-deploy osd create --data /dev/sdb node1
ceph-deploy osd create --data /dev/sdb node2
ceph-deploy osd create --data /dev/sdb node3
#4.查看信息
ceph -s
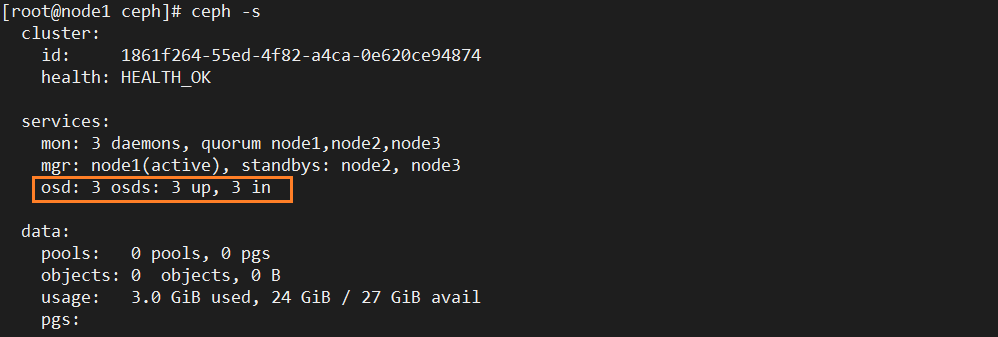
4.原生操作
#添加池
ceph osd pool create test_pool 128
#查看池pg数量
ceph osd pool get test_pool pg_num存储测试
#添加数据
#把本机的/tmp/1.txt文件上传到test_pool,并取名为1.txt
rados put 1.txt /tmp/1.txt --pool=test_pool
#查看数据
rados -p test_pool ls
#删除数据
rados rm 1.txt --pool=test_pool删除池
vim /etc/ceph/ceph.conf
#添加如下内容
mon_allow_pool_delete = true
#同步配置到其他机器
ceph-deploy --overwrite-conf admin node1 node2 node3
#重启服务
systemctl restart ceph-mon.target
#删除池
ceph osd pool delete test_pool test_pool --yes-i-really-really-mean-it
5.文件存储
要运行Ceph文件系统, 必须先创建至少带一个
mds的Ceph存储集群Ceph MDS: Ceph文件存储类型存放与管理元数据metadata的服务
MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务
服务端开启:
#创建mds服务
ceph-deploy mds create node1 node2 node3
#创建池,用于存储数据
ceph osd pool create cephfs_pool 128
#创建池,用于存储元数据
ceph osd pool create cephfs_metadata 64
#查看池信息
ceph osd pool ls
#创建ceph文件系统
ceph fs new cephfs cephfs_metadata cephfs_pool
ceph fs ls
#开启
ceph mds stat
客户端使用:
ceph默认启用了cephx认证, 所以客户端的挂载必须要验证
使用前拷贝服务端秘钥 cat /etc/ceph/ceph.client.admin.keyring

#创建文件记录密钥字符串
vim /root/admin.key
#添加从服务端拷贝的key
#挂载使用(挂载的节点需要安装了mom,mom的端口为6789)
mount -t ceph node1:6789:/ /test -o name=admin,secretfile=/root/admin.key删除文件存储
#取消挂载
umount /test/
#停掉所有mds,每台机器(node1,node2,node3)
systemctl stop ceph-mds.target
#删除文件系统及对应池
ceph fs rm cephfs --yes-i-really-mean-it
ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it
ceph osd pool delete cephfs_pool cephfs_pool --yes-i-really-really-mean-it
#启动所有mds,每台机器(node1,node2,node3)
systemctl start ceph-mds.target6.块存储
创建块存储
第一步:在node1上同步配置文件到client
ceph-deploy admin client第二步:客户端创建存储池并初始化
#建立存储池
ceph osd pool create rbd_pool 128
#初始化
rbd pool init rbd_pool第三步:创建存储卷
#创建存储卷
rbd create volume1 --pool rbd_pool --size 5000
#查看池中的存储卷
rbd ls rbd_pool
#查看卷信息
rbd info volume1 -p rbd_pool第四步:将创建的卷映射为块设备
#因为rbd的一些特定并不支持,则禁用掉相关特定,否则会提示失败,
rbd feature disable rbd_pool/volume1 exclusive-lock object-map fast-diff deep-flatten
#映射
rbd map rbd_pool/volume1
#查看映射
rbd showmapped
#如果想取消映射则
rbd unmap /dev/rbd设备名第五步:使用
mkfs.xfs /dev/rbd0
mount /dev/rbd0 /test/块存储扩容与裁剪
在线扩容
#扩容
rbd resize --size 8000 rbd_pool/volume1
#更新变化
xfs_growfs -d /mnt/裁剪
注意:裁剪不支持在线操作,裁剪后需要重新格式化再挂载
rbd resize --size 5000 rbd_pool/volume1 --allow-shrink
umount /test/
mkfs.xfs -f /dev/rbd0
mount /dev/rbd0 /test/删除块存储
umount /mnt/
rbd unmap /dev/rbd0
ceph osd pool delete rbd_pool rbd_pool --yes-i-really-really-mean-it7.对象存储
使用时并不关心数据的存储形式,只需要通过结果去访问,
get下载,put上传
第一步:
node1创建ceph对象网关
ceph-deploy rgw create node1
lsof -i:7480第二步:
node1创建测试用户
radosgw-admin user create --uid="testuser" --display-name="First User"
#需要用到的信息为 access_key secret_key,用于连接对象存储网关第三步:
客户端通过S3连接ceph对象网关
yum install s3cmd
#创建用户key文件
vim /root/.s3cfg
#添加如下内容
[default]
access_key = 6TZ1FIG20SA29K5ZYVXX
secret_key = AHN7N2veegREjtMse1YR1tbAoViuEz769TvVTHqO
host_base = 10.1.1.91:7480
host_bucket = 10.1.1.91:7480/%(bucket)
cloudfront_host = 10.1.1.91:7480
use_https = False测试
#1.创建桶
s3cmd mb s3://test_bucket
#2.查看桶信息
s3cmd ls
#3.上传文件到特定桶
s3cmd put /tmp/1.txt s3://test_bucket
#4.下载文件
s3cmd get s3://test_bucket/1.txt
#5.更多
s3cmd --help8.ceph-dashboard
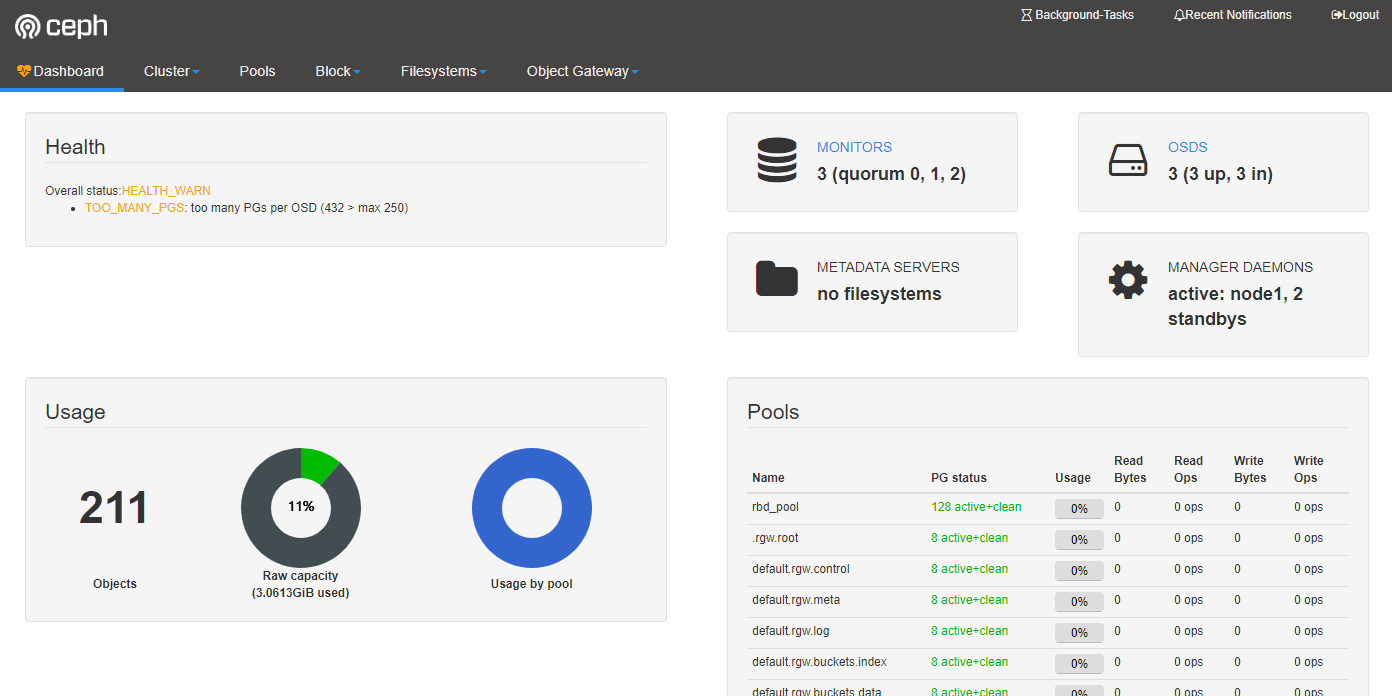
对ceph存储系统可视化监视
第一步:通过ceph -s来查看mgr的active节点
第二部:在mgr的active节点上进行开启dashboard
#开启
ceph mgr module enable dashboard
#创建自签名证书
ceph dashboard create-self-signed-cert
#生成秘钥对
mkdir /etc/mgr-dashboard
cd /etc/mgr-dashboard/
openssl req -new -nodes -x509 -subj "/O=IT-ceph/CN=cn" -days 365 -keyout dashboard.key -out dashboard.crt -extensions v3_ca第三步:
#配置
ceph config set mgr mgr/dashboard/server_addr 10.1.1.91
ceph config set mgr mgr/dashboard/server_port 8080
#重启
ceph mgr module disable dashboard
ceph mgr module enable dashboard
#查看访问地址
ceph mgr services
#设置账号密码
ceph dashboard set-login-credentials admin admin第四步:访问

其他
1.Linux 挂载ntfs格式的移动硬盘
linux内核支持ntfs,但是centos7并没有加上此功能。
解决方法有两个,一是重新编译内核,二是安装软件
#安装软件,需要有epel源
yum install ntfs-3g
#挂载使用
mount.ntfs-3g /dev/sdb1 /mnt2.losf
#查看端口
lsof -i:80
#查看目录被那个进程占用
losf /目录